
Building Low Latency Streaming Data Pipelines - Part 1
As an engineer, I know firsthand the challenge of keeping up with the ever-growing amounts of data generated in real time. The demand for low-latency streaming ETL pipelines is at an all-time high. I’m here to share my learnings and experiences building these powerful tools. Join me as we explore cutting-edge techniques and technologies revolutionizing real-time data handling.
Streaming Platforms
Event streaming refers to a data processing architecture where real-time data is continuously ingested, processed and delivered in an organized manner. AWS Kinesis, Apache Kafka, Amazon MSK, Confluent Cloud and Azure Event Hubs are popular event streaming platforms that allow for scalable, fault-tolerant and low-latency data processing. These platforms provide a central hub for ingesting and distributing real-time data streams for further processing and analysis.
Event streaming tools are typically used for real-time data processing and analysis. A generic workflow for these tools involves the following steps:
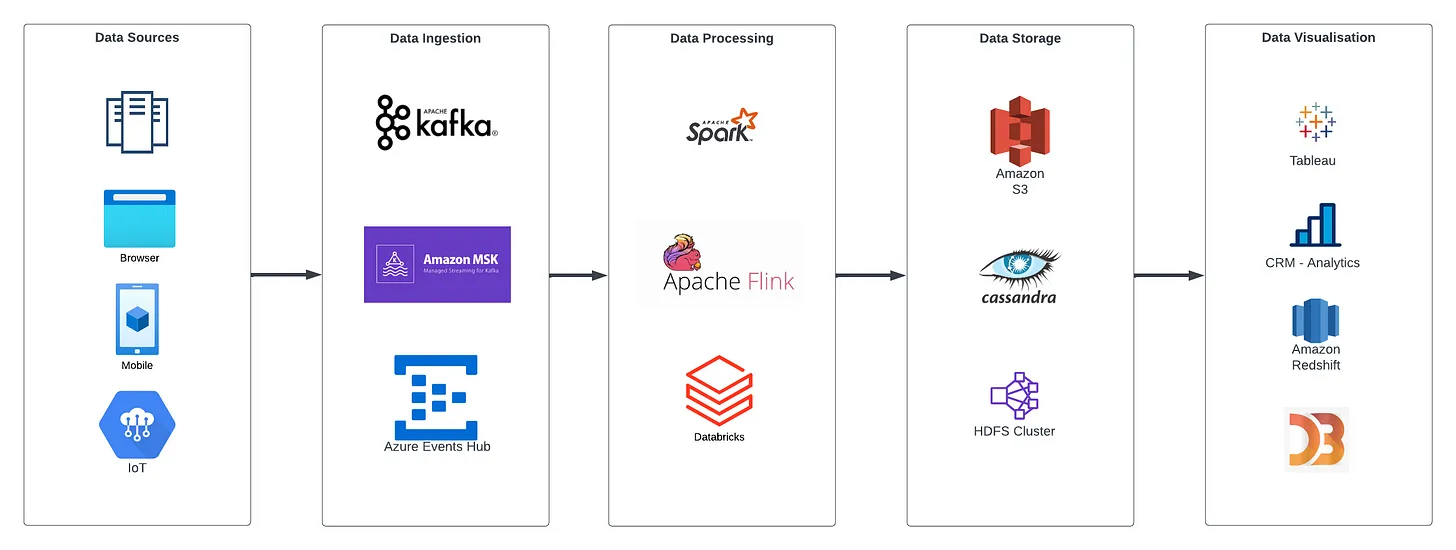
-
Data collection: The data is collected from various sensors, logs, databases, and APIs.
-
Data Ingestion: The collected data is then ingested into the event streaming platform.
-
Data Processing: The ingested data is processed in real-time to extract insights, trigger events, and perform actions. This may involve data enrichment, data transformation, and data analysis.
-
Data Storage: The processed data is then stored in a data store, such as a database, data warehouse, or data lake, for future analysis and reporting.
-
Data Visualization: The processed data can then be visualized using dashboards and reports to gain insights and make informed decisions.
Streaming workflows are popular for real-time data processing due to big data and IoT generating massive amounts of data that traditional batch processing can’t handle. Streaming pipelines allow new data to be used for analytics and ML for faster, better decisions and improved customer experiences. This leads to organizations being able to react quickly and improve business operations.
Overview of building a data pipeline with Apache Kafka
General overview of the steps to build a streaming data pipeline with Apache Kafka:
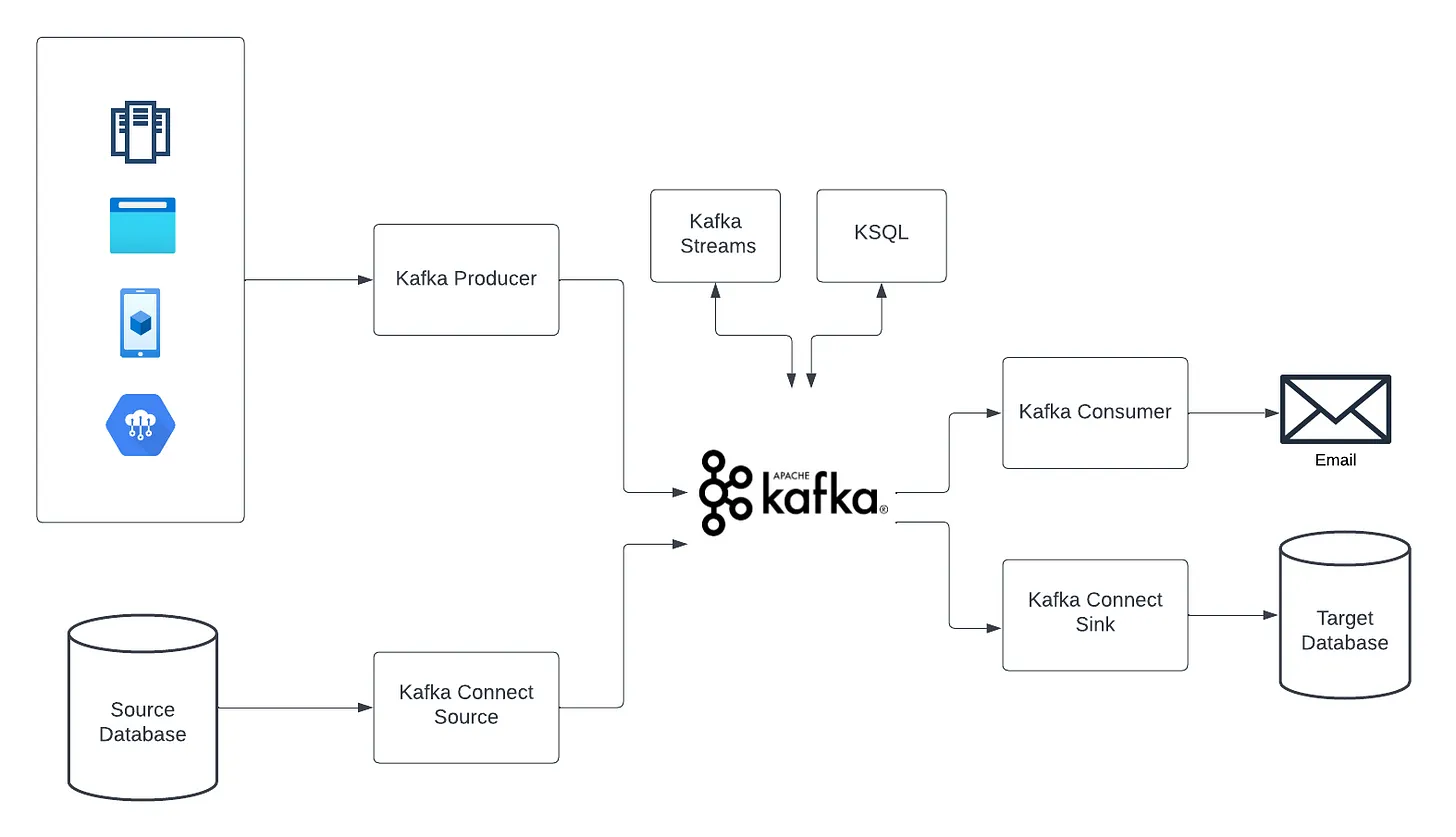
-
Set up a Kafka cluster: You can set up a Kafka cluster on-premise, in the cloud, or use a managed service like Confluent Cloud.
-
Define the Kafka topics: A topic is a category or feed name to which records are published. You must define the topics you need for your data pipeline and configure their replication, partitioning and other settings.
-
Produce data to the Kafka topics: You can produce data to the Kafka topics using Kafka producers. You can write data on topics in various programming languages, including Java, Python, C++, and more.
-
Write a consumer application: A consumer application reads data from the Kafka topics and processes it as per your requirements. You can write consumer applications in various programming languages.
-
Store processed data: You can store the processed data in a database, data lake, or any other storage system.
-
Monitor the pipeline: You need to monitor the pipeline to ensure it’s running smoothly and troubleshoot any issues if they arise. You can use tools like Confluent Control Center or Metrics Reporter to monitor the pipeline.
Handling high-volume data workloads
Heavy workloads can affect the latency and performance of a pipeline. To keep up with the demand. In such a scenario, auto-scale can be implemented in the following steps:
-
Monitor pipeline metrics: Monitor critical metrics such as incoming data volume, processing time, and resource utilization to detect changes in workload.
-
Set threshold: Set thresholds for each metric that trigger auto-scaling based on the acceptable level of end-to-end latency.
-
Trigger auto-scaling: Based on the thresholds, trigger auto-scaling by adding or removing resources (such as adding or removing nodes in a cluster) to maintain optimal performance.
-
Use auto-scaling tools: Utilize auto-scaling tools provided by cloud platforms like AWS Auto Scaling, Databricks DLT, Google Cloud Auto Scaling, or Azure Autoscale to automate the process.
-
Test and refine: Regularly test the auto-scaling process to ensure it works as expected and adjust thresholds and settings as necessary.
The above process can be tedious for someone starting to build or incorporate such workflows into existing architectures. To overcome this hurdle and set up robust ETL pipelines, let’s leverage Databricks DLT(Delta Live Tables) to highlight the ease of onboarding and to set up resilient pipelines.
Delta Live Tables (DLT)
DLT is a framework from Databricks that makes ETL pipelines easier to build and maintain. It uses a simple declarative approach and fully manages batch and streaming data infrastructure, freeing users to focus on analysis and insights. Designed for real-time data and can handle low-latency pipelines directly from event buses like Apache Kafka. It is ideal for use cases that simplify their ETL process and gain real-time insights.
DLT can be declared with a standard SQL Create Table As Select (CTAS) statement and the DLT keyword “live.”
DLT with Python, the @dlt.table decorator is used to create a Delta Live Table and can directly ingest data from an event bus like Kafka using Spark Structured Streaming
The state of the pipeline is automatically managed, eliminating the need for manual checkpointing. This makes creating and maintaining fast, low-latency ETL pipelines easier than manually building an end-to-end workflow.
Look out for this space for part 2. How to practically bootstrap an ETL workflow using DLT and Kafka.
